 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAm I More Pointwise or Pairwise? Revealing Position Bias in Rubric-Based LLM-as-a-Judge
Feb 02, 2026Large language models (LLMs) are now widely used to evaluate the quality of text, a field commonly referred to as LLM-as-a-judge. While prior works mainly focus on point-wise and pair-wise evaluation paradigms. Rubric-based evaluation, where LLMs select a score from multiple rubrics, has received less analysis. In this work, we show that rubric-based evaluation implicitly resembles a multi-choice setting and therefore has position bias: LLMs prefer score options appearing at specific positions in the rubric list. Through controlled experiments across multiple models and datasets, we demonstrate consistent position bias. To mitigate this bias, we propose a balanced permutation strategy that evenly distributes each score option across positions. We show that aggregating scores across balanced permutations not only reveals latent position bias, but also improves correlation between the LLM-as-a-Judge and human. Our results suggest that rubric-based LLM-as-a-Judge is not inherently point-wise and that simple permutation-based calibration can substantially improve its reliability.
Video Region Annotation with Sparse Bounding Boxes
Aug 17, 2020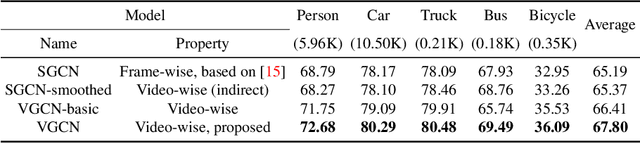
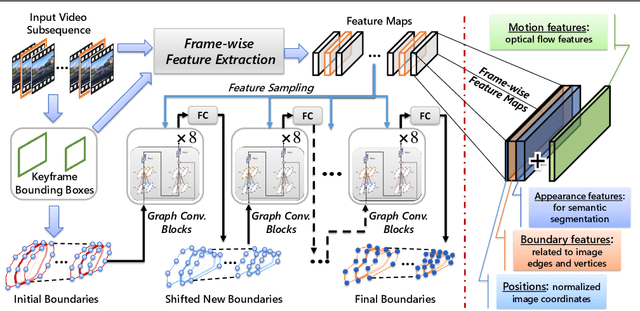
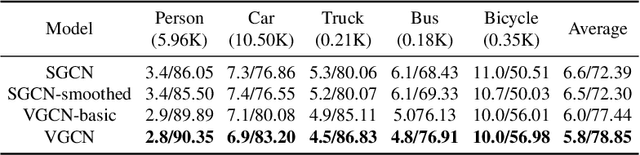
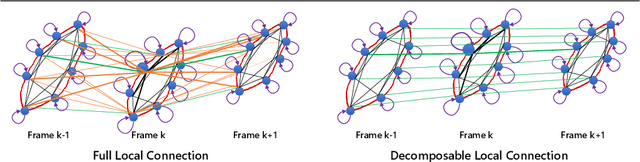
Video analysis has been moving towards more detailed interpretation (e.g. segmentation) with encouraging progresses. These tasks, however, increasingly rely on densely annotated training data both in space and time. Since such annotation is labour-intensive, few densely annotated video data with detailed region boundaries exist. This work aims to resolve this dilemma by learning to automatically generate region boundaries for all frames of a video from sparsely annotated bounding boxes of target regions. We achieve this with a Volumetric Graph Convolutional Network (VGCN), which learns to iteratively find keypoints on the region boundaries using the spatio-temporal volume of surrounding appearance and motion. The global optimization of VGCN makes it significantly stronger and generalize better than existing solutions. Experimental results using two latest datasets (one real and one synthetic), including ablation studies, demonstrate the effectiveness and superiority of our method.